
Well, there are many several changes done in improving SQL Performance such as the launch of Adaptive Query Execution, Dynamic Partitioning Pruning & much more. And we will be discussing all those changes here in this blog. So, to keep updated continue reading the blog.
Changes for SQL Performance
- New EXPLAIN Format
- Adaptive Query Execution
- Join Hints
- Dynamic Partition Pruning
So, let's understand all these in detail & see how these changes help us in performance.
1. New EXPLAIN Format
As we all know Explain command helps a lot in explaining your query & even displays how Spark has optimized the query. So, whenever we use EXPLAIN in case of Spark 2.x it shows some details as below(Refer image):

And Yes, I'm thinking the same way you are thinking right now that it is not so easy to understand this. So, to make it is easy the format of the result of this EXPLAIN command in Spark 3.0 is now changed & made easy and simple to understand in a formatted manner(Refer Image):

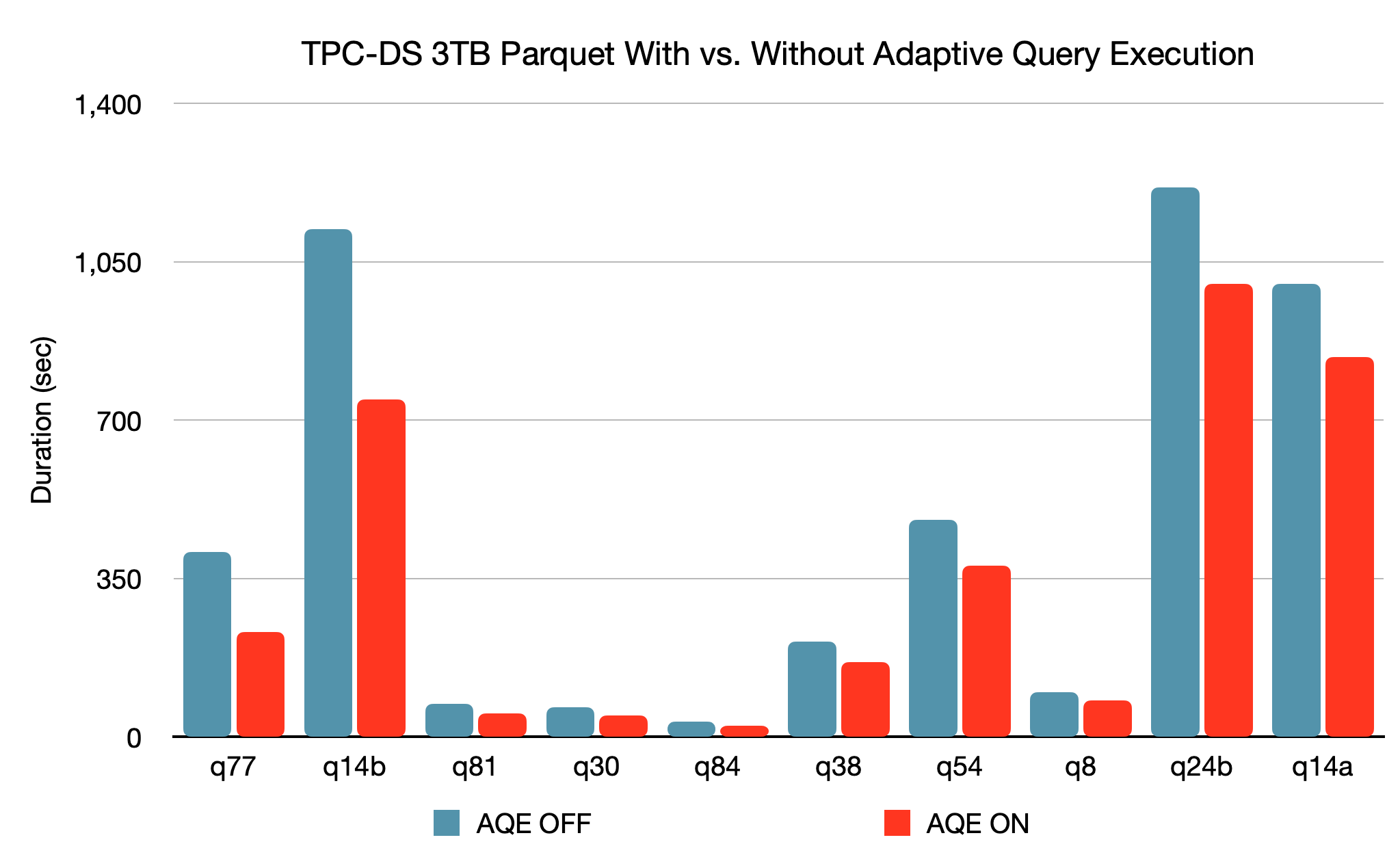
2. Adaptive Query Execution
This is one of the major changes been done in Spark 3.0 to improve the SQL performance. It improves performance and simplifies tuning by generating a better execution plan at runtime. But how?
2. 1) Automatic tuning of the number of shuffle partitions
In Spark 2.x, the total number of shuffle partitions by default was 200 and can be set using property spark.sql.shuffle.partitions which in some cases lead to an increase in I/O or disk spills & thus waste of memory.
When AQE is enabled, Dynamically coalescing shuffle partitions simplify or even avoids tuning the number of shuffle partitions. Users can set a relatively large number of shuffle partitions at the beginning, and AQE can then combine adjacent small partitions into larger ones at runtime.
To use AQE we need to set spark.sql.adaptive.enabled to true.
sparkConf.set("spark.sql.adaptive.enabled", "true")
To use the shuffle partitions optimisation we need to set spark.sql.adaptive.coalescePartitions.enabled to true.
sparkConf.set("spark.sql.adaptive.coalescePartitions.enabled", "true")
2.2) Dynamically changing of Join Strategy
As we all know when to use Sort Merge Join and when to use broadcast join. Once AQE is enabled, whenever the runtime statistics of any join are smaller than the threshold of broadcast then Spark will automatically convert Sort Merge into the Broadcast join.
2.3) Dynamically optimizing skew joins
We all know that Skewed join is very slow in Spark 2.x this is because join time is dominated by processing the largest partition.
But after enabling AQE, the larger partition is split into multiple partitions which obviously optimizes the performance makes it process faster.
To enable this property need to set below configuration:
sparkConf.set("spark.sql.adaptive.skewJoin.enabled", "true")
3. Join Hints
Join Optimization hints basically optimizes your query by reading only the data you need. It enables the users to override the optimizer to select their own Join Strategies.
In Spark 2.x, there was only 1 Join type which can be used in SparkSQL i.e Broadcast Join. This was basically used when the size of the table is bigger than the broadcast threshold & can be used as below:
val df = df1.hint("broadcast").join(df2,"Id")

In Spark3.0, there are 4 Join types:
a) Broadcast Join
b) Sort Merge Join
c) Shuffle Hash
d) Cartesian
3.1) Broadcast join
Same as Spark 2.x, there is no change as such in the Broadcast join.
3.2) Sort Merge Join
It can handle any data size & is most robust. It actually shuffles and sorts data and can slow when the table size is small.
val df = df1.hint("merge").join(df2,"Id")

3.3) Shuffle Hash Join
It can handle large tables. It does shuffles but doesn't sort data and will throw OOM exception if the data is skewed. It is a join where both dataframe are partitioned using the same partitioner. Here join keys will fall in the same partitions.
val df = df1.hint("shuffle_hash").join(df2,"Id")

3.4) Cartesian Join
It is a type of join where two dataframe are joined using all rows. And it doesn't require any join column.
val df = df1.hint("shuffle_replicate_nl").join(df2)

4) Dynamic Partition Pruning
- It optimizes your query by reading only the data you need.
- Implemented both on the logical plan optimization and physical planning. Optimizes queries by pruning partitions read from a fact table by identifying the partitions that result from filtering dimension tables.
- Create Logical plan by - column pruning, constant folding, and filter push down.
- Logical planning level to find the dimensional filter and propagated across the join to the other side of the scan.
- Physical level to wire it together in a way that this filter executes only once on the dimension side and then create a broadcast variable.
- Then the results of the filter get into reusing directly in the scan of the table. And with this two-fold approach, we can achieve significant speedups in many queries in Spark.
(Just a brief, will write a separate detailed blog on Dynamic Partition Pruning)
I hope you have got a good understanding of Spark 3.0. In our next blog, we will discuss Dynamic Partition Pruning in detail.
If you like this blog, please do show your appreciation by hitting like button and sharing this blog. Also, drop any comments about the post & improvements if needed. Till then HAPPY LEARNING.
Thanks for this great summary!
ReplyDeleteThanks Dokect. Glad you like it.
DeleteI appreciate you taking the time and effort to share your knowledge. This material proved to be really efficient and beneficial to me. Thank you very much for providing this information. Continue to write your blog.
ReplyDeleteData Engineering Services
Data Analytics Solutions
Artificial Intelligence Solutions
Data Modernization Services
I appreciate you taking the time and effort to share your knowledge. This material proved to be really efficient and beneficial to me. Thank you very much for providing this information. Continue to write your blog.
ReplyDeleteData Engineering Services
Data Analytics Solutions
Artificial Intelligence Solutions
Data Modernization Services
I appreciate you taking the time and effort to share your knowledge. This material proved to be really efficient and beneficial to me. Thank you very much for providing this information. Continue to write your blog.
ReplyDeleteData Engineering Services
Data Analytics Solutions
Artificial Intelligence Solutions
Data Modernization Services
I appreciate you taking the time and effort to share your knowledge. This material proved to be really efficient and beneficial to me. Thank you very much for providing this information. Continue to write your blog.
ReplyDeleteData Engineering Services
Data Analytics Solutions
Artificial Intelligence Solutions
Data Modernization Services
I appreciate you taking the time and effort to share your knowledge. This material proved to be really efficient and beneficial to me. Thank you very much for providing this information. Continue to write your blog.
ReplyDeleteData Engineering Services
Data Analytics Solutions
Artificial Intelligence Solutions
Data Modernization Services
I appreciate you taking the time and effort to share your knowledge. This material proved to be really efficient and beneficial to me. Thank you very much for providing this information. Continue to write your blog.
ReplyDeleteData Engineering Services
Data Analytics Solutions
Artificial Intelligence Solutions
Data Modernization Services